A 3-Brain Architecture for Brain-Like Intelligence
1 Introduction
1.1 Context
In the development of learning systems and neural networks, the issue of complexity occurs at many levels of analysis.
Most of the literature on complexity and neural networks addresses the task of supervised learning -- the fundamental task of learning a mapping from an input vector X(t) to a vector of targets Y(t), based on training data consisting of examples of the two vectors. This is an extremely important topic, where insights into alternative concepts and measures of complexity will be very important to practical results in engineering [14, 2 chapter 10]. Further research on this topic will be crucial to the development of supervised learning components which are powerful enough to permit truly brain-like capabilities in larger intelligent systems.
This paper will address an equally important, complementary aspect of the complexity issue -- the problem of how to build larger-scale intelligent control systems able to cope with truly large and complex environments. In particular, the paper will describe the design of a new class of systems to perform optimization over time. Many other papers (e.g. in [1,15-18]) have discussed why this is a reasonable approach to explaining and replicating the kind of higher-order intelligence found in the mammalian brain; however the previous designs based on that aproach have had certain limitations so far in their ability to handle truly complex environments. These designs have been more than enough for the current types of challenges being addressed at the frontiers of control engineering[2]; however, in order to handle those kinds of complexity which the mammalian brain can cope with, one must upgrade these designs, so as to exploit the phenomena of “temporal chunking” and “spatial chunking,” as will be discussed below. A large part of the challenge here is to build a truly brain-like neural learning-based design which can learn to achieve the kinds of capabilities which have been already achieved in some special applications, using mainly hard-wired algorithms, in the domain of artificial intelligence. This paper will discuss how to meet that challenge.
In many ways, the design approach given here is a beginning rather than a conclusion. The paper does lead to many possible variations in how to implement the approach, and and many questions about what will work best, under what conditions. It also makes very strong assumptions about the reader’s knowledge of prior knowledge, especially involving the papers cited below.
The text which follows is taken directly from an international patent application filed on July 4, 1997, by this author, in association with Scientific Cybernetics, Inc. That application also incorporated several of the papers cited below, and some additional information on possible applications, for example, in strategic game-playing, in hypersonics, in the control of complex heat exchanger systems or fuel processors, and in distributed large-scale network control. For the sake of authenticity and timeliness, the text is being published without alteration, except for the addition of some new references and for copy editing required to meet the standards of this publisher.
The relation between this design and the brain has also been discussed with the neuroscientist and psychologist Karl Pribram, as reported in part in [19]. The “decision blocks” which form the core of this design could be thought of either as “task modules” (as in Pribram’s earlier work) or as “episodes” as his in more recent work[20]; in fact, the proposed structure has the ability to learn to be more goal-oriented (like a task module) or to be more reactive in nature (like an episode processor), depending on what works best in specific situations. The “loops” or “layers” in the basal ganglia/cortex/thalamus circuit have been discussed not only by Brooks, but also by John Taylor, James Houk, Seng-Beng Ho and several others
whose thoughts and guidance I am most grateful for.
1.2 A Three-Brain Architecture for Artificial Intelligence
The purpose of this paper is to describe a method for building a new type of general-purpose artificial intelligence which will be called a “3-brain system” or “3-brain architecture.”
This architecture was originally motivated by an effort to understand and replicate the kinds of problem-solving capability and learning which exist in the brains of mammals [1]. The details of these efforts are described in several papers filed with the preliminary patent applications and included as part of this disclosure. An additional paper, also included [2], describes some of the underlying engineering principles and ideas for how to use these designs in practice. Some of these papers were written on government time, but the original ideas therein were developed by the author independently, usually in periods of reflection outside of the office.
The 3-brain architecture is not, strictly speaking, a single design. It is a design methodology, which can be implemented in a variety of ways, on a variety of platforms. The architecture can be embodied in chips, in opto-electronic hardware, in biomolecular hardware, or in software. As a practical matter, the software emulation will probably come first, in order to permit the careful evaluation and tradeoff studies necessary to justify the more expensive step of building dedicated hardware.
This design methodology may be thought of as an improvement to certain architectures previously developed (and partly patented) by this author. More precise-ly, it is an extension of the model-based adaptive critic (MBAC) or “brain-like intelligent control” designs described in the attached papers. Those designs, in turn, may be seen as extensions of Ron Howard’s methods of dynamic programming [3].
In general, all of these designs can be expressed as designs for learning-based maximization of utility over multiple time periods into the future. This includes “reinforcement learning” as a special case [4]. In reinforcement learning, an intelligent system is given access to a set of sensor inputs, a set of actuators which it controls (i.e. its outputs are wired up to the actuators), and to a monitor which evaluates its performance or “utility” (U). Through learning and/or exploration, it develops a strategy or “policy” of action which enables it to maximize (or minimize) total utility in the future. These reinforcement learning systems are intended to be general-purpose systems, because the same learning system can be applied to different applications, simply by having it learn to adapt to these various applications sepa-rately. The 3-brain architecture is a major, qualitative improvement over the earlier designs, insofar as it has the potential ability to learn to cope with far more difficult applications. In effect, it is a general purpose system for making intelligent decisions.
This paper will describe how to build a 3-brain system, by a series of progressive improvements, starting from incremental dynamic programming, which will be reviewed. The first part of the paper will describe new designs for “temporal chunking” with reinforcement learning, in a classical context. The second part will describe how to replace the matrices in these new designs with neural networks (or similar structures), in order to permit larger-scale applications based on the ability of neural networks to approximate complex nonlinear relations in a parsimonious way. The third part will describe new, more sophisticated neural networks (and their nonneural generalizations) which should perform better than conventional neural networks as components of these designs; in addition, it will describe some possible hardware implementation of the most critical, computationally expensive components, and address the extension of this system to incorporate aspects of “spatial chunking.”
Crudely speaking, parts 2 through 4 of this paper will describe how to construct the “upper brain” and the “middle brain” as described in [1]. Part 5 will describe briefly how to attach such a higher-level intelligent system to a lower level “brain” so as to construct a complete “3 brain” system.
The technological intention here is to first build up a modular software package, in which a full three-brain system can be obtained by linking together the appropriate modules. (Before this is fully completed, however, some of the hardware development recommended in part 4 will be started, if possible.) However, for practical purposes, the user of this software will also be able to use simpler modules, or alternative modules, to fill in the various components, if he or she chooses.
The step-by-step approach to constructing this kind of intelligent system is intended to provide additional flexibility in the overall package, flexibility which a monolithic implementation would not possess.
Notice that this paper will suggest several alternate designs, based on the same general approach or method, to perform subsystem tasks. In earlier research, in past years, the author often tried to specify one best alternative for each subsystem. But experience showed that different alternatives worked better in different applications. Thus the intention is to build a general system which provides the user a choice of subsystems, so as to allow extensive tradeoff studies.
2 Time-chunked Approximate Dynamic Programming
2.1 Notation and Classical Results
In the simplest forms of dynamic programming, we assume that the environment or the plant to be controlled can only exist in one of a finite number of possible states. These possible states may be denoted as s1 ,..., si ,..., sn , where n is the number of states. At each time t, the intelligent decision-making system observes the state s(t) (where s is an integer between 1 and n), and then outputs a vector containing decisions or control variables, u(t). Usually the intelligent system will choose u(t) based upon a “policy” p which is simply a collection of rules of how to behave (to choose u) in different states s. This may be written conceptually as:
u(t) = u(s(t), p) (1)
Normally the user of the system provides a utility function U and an interest rate r. We are asked to design an intelligent system which can learn the optimal policy, the policy which at any time t will maximize:
![]() (2)
(2)
where the angle brackets denote expectation value. (It is a straightforward well-known extension of this to consider finite horizon problems, in which t goes to some finite maximum T. Also, it is common to build designs in which r is initially set to a high value -- even infinity -- in the first few iterations, and lowered slowly to the user-specified value, as a method for improving learning.)
Normally it is assumed that we know the transition probabilities as a function of action, which may be written:
![]() (3)
(3)
For a particular policy p, we may define the classic J function as:
![]() (4)
(4)
and:
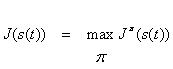 (5)
(5)
The basic theorems of incremental dynamic programming [3,5] describe the properties of this function J, which must normally obey the Bellman equation:
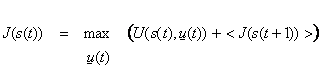 (6)
(6)
Note that this equation also provides a basis for actually choosing u(t) at any time t.
In the case where there are only a finite number of possible states s, we may define a state probability vector p by defining its components p1 ,..., pi ,..., pn as:
pi = Pr(si) (7a)
pi(t) = Pr(s(t) = i) (7b)
In this notation, we have, for any policy p:
p(t+1) = Ppp(t) (8)
Likewise, we may define the vectors Jp and Up by defining their components:
![]() (9a)
(9a)
![]() (9b)
(9b)
In this notation, equation 4 takes the form:
Jp = Up + MpJp , (10)
where we define:
Mp = (Pp)T/(1+r) (11)
2.2 Classical Approaches
In traditional incremental dynamic programming [3,5,6], the optimal policy is found by some kind of alternation between “value updates” and “policy updates.” One starts with something like an arbitrary policy p and an arbitrary estimate of the value vector J. One learns the optimal policy simply by progressive improvements in the policy and in the estimated value vector. The value updates are generally based on equations 6 and 10, translated into:
J(n+1) = Up + MpJ(n) (12)
In other words, for the current policy p, one replaces the old estimate of J (J(n))
with this new estimate (J(n+1)). In a policy update, one simply picks u(t) at each time t so as to maximize the right-hand side of equation 6, using the current estimate of J. In particular, one may do all this for the entire set of states (as implied by equation 12) or for one state at a time. The MBAC designs mentioned above provide neural network approximations to these kinds of updates.
Broadly speaking, there is another important choice of strategies in making these kinds of updates. In a passive strategy, one simply assumes the current policy p, and carefully works out J in detail. In the active approach, one explicitly designs the value-updating system so as to permit more frequent changes in the policy p and more explicit allowance for the effects of such changes.
2.3 Temporal Chunking: Multiresolutional Designs
Traditional approaches to dynamic programming and to approximate dynamic programming (ADP) are generally based on “backups” or “value updates” from time t+1 to time t, as implicitly assumed in equation 12. But in a real-time control system, the interval between time t and time t+1 (the sampling interval) may be very short. The literature on artificial intelligence has stressed the need to jump over longer time intervals [7]; however, this kind of “temporal chunking” has yet to be implemented in effective learning-based ADP designs.
In theory, the usual ADP designs should all converge to the correct policy, anyway, if given enough time. But there is a problem here with computational cost and computational complexity.To put it another way, new designs which inject time chunking into ADP should lead to reductions in computational cost and complexity, which in turn should make it possible to handle more complex applications at acceptable cost.
To understand these cost issues, return to equation 12. For simplicity, assume a purely passive approach, in which we try to find the correct J function (Jp, in effect) for a fixed policy p. Assume that the initial estimate of J -- J(0) -- is simply set to equal U. In that case, it is easy to see that:
![]() (13)
(13)
Thus after n complete value updates, the “critic” (the estimate of J) “sees” only n periods of time into the future, in effect. Equation 13 is just an estimate of the true value:
Jp = (I - Mp)-1 U (14)
In order to learn the true J much more quickly, one may exploit the following numerical identity (for the limiting case, assuming no singularities, as usual):
Jp = ... (I + (Mp)16)(I + (Mp)8)(I + (Mp)4)(I + (Mp)2)(I+Mp)U (15)
Using this approach, after only n steps of calculation, one “sees” 2n periods of time into the future. There are two ways to implement this approach:
1. For each number j, from j=1 to “infinity”, multiply J(j-1) on the left by Mp 2j times, and then add the result to J(j-1), in order to calculate J(j).
2. To start with, set M0=Mp. Then for each iteration j: first set Mj = Mj-1Mj-1;
then calculate:
J(j) = J(j-1) + Mj-1J(j-1) (16)
There are many possible extensions of this, such as the obvious generalizations based on the repeated application of:
Jnk = (I + (Mp)n + (Mp)2n + ... + (Mp)n(k-1)) Jn , (17)
where I now define (just for equation 17):
![]() , (18)
, (18)
and where the parameter k can be set to any integer >1, and even varied from iteration to iteration if desired.
These methods, collectively, will be henceforth called Multiresolutional ADP. In conventional artificial intelligence, they would correspond to systems based on “clock-based synchronization.”
It should be noted that the n-step methods described by Sutton [6] have some relation to these methods. However, Sutton’s designs permit a foresight extension of only a factor of 2 (or of k), rather than 2n or kn! He does not demonstrate any awareness of the crucial tricky relation in equation 15.
Both in Multiresolutional ADP and in other temporal chunking designs, it can be extremely useful (when possible and appropriate) to represent a utility function as a growth process, i.e. as:
U(s(t),u(t)) = V(s(t)) - V(s(t-1)), (19)
for some reasonable function V, in the case where r=0. This can permit a substantial reduction in the apparent complexity of the calculations.
2.4 Temporal Chunking: Two-Level Event-Based Designs
If the matrix Mp were a fully populated (fully connected) matrix, it would be very difficult, in principle, to improve upon these multiresolutional methods. However, as a practical matter, the matrix Mp will usually be extremely sparse, in large real-world applications. To reduce the costs still further, in the finite state situation, one can use a domain decomposition approach, in order to exploit this sparsity.
To begin with, let us consider a simple partition design for implementing this approach. Let us assume that the possible states of the plant have been partitioned into blocks. Thus every state s will be denoted by sA,i , where A is the block number and i is the number of the state within the block. The key to this approach is to find a partition such that Pr(B(t+1),j(t+1) | A(t),i(t)) will equal zero, except when block B happens to be one of a very small set of blocks “near to” A. More precisely, if n(A) is the set of blocks B such that a direct transition from A to B is possible, then the key is to find a partition such that n(A) is as small as possible for the “average” block A. This is a two-level design, where the upper level involves the choice of blocks A or B, and the lower level involves the choice of states i and j.
Starting from any block A, for a fixed policy p, we now have two sets of transition matrices to consider: PA, which represents transitions within block A, and PBA, which represents transitions from block A to a different block B. Mirroring equation 11, we then arrive at the matrix MA and the matrices MAB.
For any vector v defined over all of the possible states of the plant, let us write “v |A” to represent that portion of the vector v which applies to states within block A. For example, if there are 100 possible states of the system, of which 15 are in block A, then v will be a vector with 100 components, and v |A will be a vector 15 components, extracted from v. In this notation, the Bellman equation (equation 10) implies, for each block A:
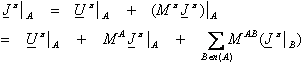 (20)
(20)
By matrix algebra, this implies:
![]() (21)
(21)
Let us define:
![]() (22a)
(22a)
![]() (22b)
(22b)
With these definitions, equation 21 reduces to the following fundamental equation for event-based chunking:
![]() , (23)
, (23)
where the asterisk indicates matrix multiplication. Equations 22a and 22b imply the following recurrence relations, similar to the Bellman equation:
![]() (24)
(24)
![]() (25)
(25)
The simple partition design is defined as any incremental dynamic programming design in which:
1. JA and JAB are updated by some sort of use of equations 24 and 25;
2. The global estimate of J is updated or calculated by use of equation 23, in some way;
3. Policies or actions are updated based on J, as usual.
As with ordinary incremental dynamic programming, value updates (updates of J, JA or JAB) or policy updates may be global (all states at once) or local (e.g. state-by-state), and may be scheduled in a variety of ways.
Furthermore, one can reduce computational cost (or architectural complexity) by a considerable amount, by performing only the most essential calculations at appropriate times. For example, in order to develop long-term foresight most efficiently, one can use equation 23 very often only to update J for those states in blocks A which can be reached directly, in one step from states in other blocks. Values of J in other states are needed only when updating actions; such updates typically require the calculation of only a few J values, for the block in which action decisions are currently being updated. Formally, if a state i in block A can be reached directly in one step from block B, then state i will be called a “post-exit” state of block B. Global foresight requires only that J be updated in post-exit states, because those are the states whose J values are actually used in the far right term of equation 23.
2.4.1 Variations to the Simple Partition: Focused Partition and ADAC
There is a very straightforward variation of the simple partition design which has many of the same properties. This variation may be called the focused partition design. In this variation, we define the exit states of any block A as the states from which a direct transition to other blocks is possible. One tries to find a partition which minimizes the number of exit states. In the simple partition design, we always consider those components of a vector v which apply to states within the block A. In the focused partition variant, we consider those states in A which are not exit states, plus those states of other blocks which can transition to block A in a single step. The resulting changes in structure are straightforward, but of some significance. For example, in equation 23, instead of considering J values for state in other blocks B on the far right, we consider only J values for the exit states of block A. But the matrices JA and JAB are extended, so as to provide components of the J values for exit states of some other blocks. In fact, it is most convenient simply to update additional vectors, J+A , which estimate the values of J for the exit states of each block A. It is not necessary to maintain estimates of J for other states. The major value of this variant is to reduce the size of the rightmost term in equation 23. This is especially useful in the completely active variant, where it is important to minimize the number of inputs to the various neural networks.
There is another variant here which should be mentioned, for the sake of completeness, even though it is not a preferred variant. It is possible to define:
J’A(i,u) = U(i,u) + (MA(u)JA) , (26)
in rough notation, where “I” represents a state within block A. This is the most natural way to apply the notion of “Action Dependent HDP” or “Q learning” [8,ch.13] in this context. ADHDP and Q-learning are both examples of what is called “ADAC,” the Action-Dependent Adaptive Critic, in [8].
One can adapt J’A based on transitions within block A, using essentially the same kind of update we would use for JA, just as the classic method ADHDP is essentially the same as HDP, with the same minor variations. This is not the preferred version for large-scale problems, because it entails the same sort of weaknesses (with a few advantages) of ordinary ADHDP and Q learning [8]. However, when the choice of actions is actually very limited an state variables are very complex, this variation can be useful. For low-level control, the choice of actions is usually more continuous, but for higher-level decisions the important choices sometimes are more discrete.
2.4.2 Step-by-Step
Approaches to Learning J, JA,
JAB or J’A
In a pure finite-state problem, direct matrix updates of J, JA, JAB or J’A based on these equations can be very efficient. However, the ultimate purpose of describing the finite-state case in this paper is to set the stage for the full preferred form of the 3-brain architecture, which involves neural networks and learning for large-scale problems. For the sake of simplicity (and step-by-step implementation), the neural net designs will be presented as extensions of finite-state methods.
For neural network designs, especially, it is important to consider methods for updating J, etc., on a step-by-step basis. Such methods can be studied and used in the finite-state case as well.
Even in the finite-state case, there are several choices for how to update JA and JAB, essentially the same as the usual choices in updating J in ordinary ADP [8]. One choice is simply to use the matrix equations, as written (or restricted to exit states, where applicable), for global value or policy updates. Another is to use state-by-state updates. In conventional state-by-state updates, for example, it is common [8] to change the estimate of J(s(t)) in proportion to:
J(s(t+1))/(1+r) + U(s(t),u(t)) - J(s(t)), (27)
where s(t+1) may be the state actually observed after state s(t), as we observe the actual plant, or where s(t+1) may be simulated based on the correct transition probabilities (P). In our case, we may apply exactly the same approach to updating JA. In rough notation, we may update our estimate of JA in any state s(t) as follows:
new JA(s(t)) = old JA(s(t)
+ LR*( “JA(s(t+1))”/(1+r) + U(s(t),u(t)) - old JA(s(t))) , (28)
where LR is some kind of learning rate. (LR will usually be less than zero because of the stochastic nature of this process.) In this equation, “JA(s(t+1))” usually represents our estimate of JA(s(t+1)), which we are not updating here, unless s(t+1)=s(t), in which case we use the old estimate. However, in the case where s(t+1) is not in block A, JA(s(t+1)) is not defined; in that case, we use zero instead of JA(s(t+1)) in equation 28. This is not an ad hoc fix; instead, it follows directly from analyzing equation 24.
This same approach can also be applied in updating the JAB matrices. Notice that JijAB has an important intuitive interpretation: if the system starts out in state i in block A, then JijAB represents the probability that the next future state outside of block A will be state j in block B, discounted by the interest rate r (if r¹0). The simplest appropriate update rule is:
new JjB(s(t)) = old JjB(s(t) + LR*(“JjB(s(t+1))”/(1+r) - old JjB(s(t)), (29)
where I have not bothered to write the additional indices (i and A) representing state s(t), and where “JjB(s(t+1))” represents the old estimate of JijAB except in the case where s(t+1) is no longer in block A. In that case, “JjB(s(t+1))” is defined as 1, if s(t+1) is state j in block B, but otherwise zero.
Actually, there is a further variation of this adaptation procedure for JAB which -- though more complex -- may improve convergence in some cases. One may define a new global transition probability:
![]() (30)
(30)
One can then adapt this transition probability using an update rule essentially identical to equation 29, except that it uses a term “PiAB”, which equals 1 if and only if s(t+1) is in block B. One can adapt a conditional J value, J’jB , using the same adaptation rule as equation 29, with J replaced by this J’, except that adaptation is skipped whenever s(t+1) is not in block A or block B. In this variation, one continually updates PAB and J’AB instead of JAB, and one replaces the use of JAB by exploiting the relation:
![]() (31)
(31)
All of these state-by-state update procedures are adaptations of the classic methods first proposed as Heuristic Dynamic Programming [8] and later elaborated under the name Temporal Difference methods. As an alternative to such methods, there are of course more classical methods (usually less efficient) for estimating transition probabilities in this kind of situation. For example, in each transit through block A, one may simply record every state visited. For every state in block A, one maintain a description of the distribution of the corresponding eventual exit state. One may then update each such description as soon as one exits A again, and then one can delete the record of this transit. It is straightforward to adapt this method to a neural network approach as well, similar in spirit to Widrow’s original adaptive critic blackjack player, briefly discussed in [2]. Although these approaches are expected to be less robust than the state-by-state update methods, they may be useful as part of a more complex hybrid approach combining both.
Finally, it is also possible to use step-by-step learning procedures to update the global estimates of J, based on equation 23. It has already been noted that we do not actually need to update estimates of J for every state. It is enough simply to update estimates of post-exit states (in the simple partition case) or of exit states (in the focused partition case). For updating action policies it is enough, in effect, to use equation 23 directly to calculate J(s(t+1)) for particular states s(t+1) which might result from u(t).
For updating the essential J values, consider the analogy between equation 23 and the Bellman equation (equation 10), for the simple partition case. Equation 23 is like the Bellman equation, except that s(t) in the Bellman equation corresponds to the first state encountered when entering block A, while s(t+1) corresponds to the first state (j) encountered when exiting the entire block A. This suggests three natural ways to update J on a state-by-state basis. First, we can remember the initial state i encountered when entering block A, and then, upon exiting block A, adapt the estimate of Ji so as to be closer to:
JiA + (Jj/ (1+r)t) , (32)
where t is the number of time periods between entry and exit, which must be remembered as well unless r=0. This is a reality-based update. A reality-based update can only be undertaken once per t time periods, roughly, because it requires that we wait from the start to the exit from the block. Second, we can store i, j and t in some kind of memory, and do a memory-based update at some later time. (This is an example of the learning strategy called “syncretism” in [8,ch.3].) Third, we can pick a possible or remembered (or just conceivable) value for i, and then simulate j (and t, if r does not equal zero). Notice that the matrices JijAB, made up of transition probabilities, can be used to perform this kind of simulation, without any need to simulate intermediate states. Simulation-based updates and memory-based updates of J can be done much more frequently than reality-based updates, because they require only one cycle time of computation. Therefore, the preferred variation for a full, efficient, parallel 3-brain design would involve frequent simulation-based updates and memory-based updates of J, especially for calculations involving large chunking intervals t, even during normal real-time operation of the system.
In actuality, for a neural-network approximation of this system, to be described in section 3, there is an easier step-by-step adaptation rule for these post-exit J estimates. We can simply set:
new Ji = old Ji + LR*(JA(i) + “JB(i, J |B)” - old Ji) , (33)
where the term in quotations refers to the output of a neural network (or other supervised learning system) which is trained to input the J estimates for the post-exit states of block A and a specification of a state i in block A, and to output the complete JAB term for that state i (i.e., to output the summation in equation 23.)
Equation
33 may be called a backwards value update, to contrast it against the
update procedure related to equation 32, which may be called a forwards
value update. (In similar language, equation 23 is used in the classical
approach to provide a backwards value update, but a matrix-based update rather
than a state-by-state
update. Later, neural network approximations provide still
another choice between “pattern learning” and “batch learning” alternatives[2].) The tradeoff between forwards value updates and
backwards value updates is a recurrent issue, even in more complex designs. In
this context, however, the backwards value updates have an advantage, because
they are exact; by contrast, equation 32 involves the usual random disturbances
associated with any statistical sampling method, without any real cost
advantage.
2.4.3 From Passive
Design to Active Design: Locality and
Decision-Making
This section will describe further variants of these designs, also motivated by the desire to provide a basis for neural network learning extensions.
The simple partition and focused partition designs, as described above, were both derived as passive methods -- as methods for efficiently calculating J for a given action policy. To develop more active designs, one can employ two general strategies which will be explained in this section: (1) increased “locality”; (2) explicit “decision-making.” In the full, preferred version of the 3-brain architecture, both of these are used.
In locality, the idea is to make sure that the things one is learning in any region of state space (here, a block) do not depend strongly on what is observed and learned in other regions of space. Locality is already widely used as a strategy in ordinary supervised learning [2]. In that context, it is well known that local designs lead to faster and more robust learning (though often with poor generalization, for reasons which do not apply here), in part because there is no need to unlearn or relearn things as one moves from one block to another.
The simple partition and focused partition designs already provide a reasonable degree of locality. The JA and JAB matrices for a block A depend only on transition probabilities from that block . Thus the crosstangled global learning problem is decomposed into smaller local parts, such that the required foresight horizon in each part is usually very limited. (In principle, one could also apply multiresolution methods within each block, so as to accelerate equations 24 and 25; this is a straightforward application of what we have discussed so far, but it is questionable whether the brain uses such a complex design.) Equation 23 allows one to update the global values by jumping over an entire block in a single step of calculation, in effect. This is a form of event-based chunking, because equation 23 provides temporal chunking, and the chunks are defined by events (exiting from a block) rather than by predetermined time intervals.
This design is actually somewhat active, in the following sense. Actions within any block A should affect only the transition probabilities -- and hence the JA and JAB -- in that block. However, the design is not completely active or local, because the J values used when selecting actions u are the J values for the relevant block, calculated by equation 23; this calculation in turn, does depend on some J values for states in blocks B. Thus any change in those global J values would change the actions within the block. This in turn implies that the action policy within the block will depend on global variables outside the block. Thus the action policy within the block, the transition probabilities within the block, and even JA and JAB themselves, are all subject to change to some degree, depending on things outside of the block.
In order to upgrade the design to make it completely local, one can replace the matrices JA and JAB and the local action policy with neural networks or the like. Section 3 will describe this kind of process in more detail. In the classical context, JA is essentially just a lookup table which, for each state in block A, yields an estimate of JA (a component of the J function of dynamic programming). However, one can replace JA with either a neural network or a lookup table full of neural networks, which inputs both the state and the specific J values for blocks B which affect block A via equation 23. Those specific J values are the J values for the “post exit states” of block A, the states which can be reached from block A directly in a single transition. Equation 24, for example, provides the target which can be used to train that neural network (or any other supervised learning system [2]) used for that purpose. Essentially the same choice of representations also applies to the network(s) which represent JAB, although, as discussed before, there are some further variants possible for JAB to improve convergence. Even in the passive case, there are several ways to represent an action policy (exactly as in ordinary incremental or approximate dynamic programming [3,5,8]); for the completely local variant of the simple partition design, the action policy itself would also be represented either as a neural network or something similar [2], or a lookup table of separate neural networks for each state. The preferred embodiment for large-scale control tasks would involve a single neural network for each of these components. Because the dependence on information outside of block A can be accounted for by these networks, they should make it possible to learn the relevant information (the three networks, normally) depending only on information within the block itself; in principle, changes outside of the block should not require any change in these networks. This kind of complete locality has many advantages.
Experts in AI may ask how this kind of structure could accommodate rapid changes in estimates of “J” within a block, which exploit the power of local search activities. The answer, in brief, is that the neural networks used to approximate JA and JAB can have fast-learning local components (i.e. local components as in supervised learning.) There is no inherent conflict between locality as described here, and the ability to exploit the power of local search.
For a full-fledged system of brain-like intelligence, one must go even further and in notion which may be called “decision-making” (or “decisiveness” or “action chunking.”)
The partitions described above are very passive in nature. They do apply to large-scale decision problems in the real world, even more than they apply to abstract finite-state problems. They reflect the fact that the state of our world (unlike movies or TV shows) does not often change in a split second from one state to something radically different. The possibilities of transition from one state to another are very constrained, regardless of what actions we take. For a strict application of the designs discussed so far, the partitions and blocks must be defined so that they allow for any possible choice of actions. (In practice, however, if we have ruled out certain kinds of actions, we need only focus on transitions which are possible for the currently-considered choice of actions.)
In larger, more realistic problems, we can achieve a tighter partition, and therefore more efficient calculation, by using a concepts of decisions or action schemata or task modules or verbs in place of these large, passive blocks. (Sutton [6] refers to “abstract actions” in an intuitive way, which does not relate to the machinery here.)
There are several ways of implementing this idea of “decision-making.” In the pure finite-state case, one would usually require that the decision options -- like the simple partitions above -- must be specified in advance, at least in terms of an initial local action policy and in terms of the entry states and exit states. The best techniques for learning the set of options (entries, exits..) involve fuzzy chunking and such, to be discussed in a later section.
In the simplest variant, we assume that the user has supplied a list of decision-blocks, rather than a set of simple blocks. But within each decision block, there is still a choice of actions, and a definite pre-specified set of exit states and post-exit states. The one new feature is that, whenever we encounter a post-exit state, we have a choice of several possible decision blocks to enter. Thus, in any post-exit state x, we have a choice of D decision blocks we can choose from (a subset of all the decision-blocks in the system). For each block number d (where 1<d<D), there should be block-specific matrices Jd and JddB, exactly analogous to the matrices JA and JAB discussed before. But then, if we use equation 23, we would have D different estimates of the value of J(x,d), depending on the choice of decision, without even considering how to handle J|B !! Of course, the proper procedure is that, upon entering x, we choose the decision d which maximizes:
![]() (34)
(34)
Strictly speaking, we do not really need to identify blocks B as such; this is really a short-hand way of saying that the sum is to be taking over the post-exit states of decision block d. To perform this summation, we need to know the estimates of J in all the post-exit states, just as before. Note that when we decide on the decision block for state x, we can at that time update the estimate of J in that state to be closer to the estimate indicated by equation 34! Thus equation 34 is both a recipe for making decisions, and for updating global J estimates. It is a kind of higher-level Bellman equation, even more than equation 23 is!
Once we have made a decision -- i.e., entered a particular decision block -- it is appropriate to update Jd and JdB only for that decision d (not for the alternative decisions we might have made!) based on current real experience, until we have exited from that decision block.
Unfortunately for the control theorist, the simplest variant here is still not quite enough to explicitly capture the full process of decision-making by mammalian brains. Even after a decision is made, it is sometimes useful or necessary to abort the decision before the normal post-exit states are reached. There are three phenomena to be considered here: (1) failure to complete the task; (2) changing one’s mind, sometimes because of new opportunities arising, sometimes due to incipient failure, etc.; (3) modification of the goals of the task. The third of these is beyond the scope of this section. For strict locality, we can and must account for the first two simply by redefining the post-exit states to include failure states and states of changed mind. (To allow changing of minds, one applies equation 34 to all possible states where it may be reasonable to consider changing one’s mind.) But as a practical matter, it is more reasonable to build a system which tries to learn all the important exit modes, in a purely active/local manner, but which remains somewhat consistent by using equation 23 in the older passive mode (as per section 2.4.2) when unexpected exits occur. In either case, equations 23, 24, 25 and 34 remain the basis of system adaptation, both for expected post-exit states and unexpected ones.
In the limit, one might imagine using equation 23, as in section 2.4.3 and above, for all the possible decision blocks within a larger, passive block of possible states. But this simply reduces to the lower-level ADAC design (equation 26), using the larger passive block as the basis for partition! The decision-based additional locality is simply lost altogether. This analysis leads to two observations of relevance to further design work: (1) use of lower-level ADAC or mixture of expert designs to output actions can be a useful first step in suggesting initial possibilities for decision blocks, i.e. a useful part of the growing/pruning process for these systems; (2) because the ADAC approach does not fully capture the local approach, it is better -- when possible -- to try to learn the unexpected post exist states, so that they will not be unexpected in the future.
2.5 Temporal-Chunking: Multi-level Task-Based Designs
The previous discussion in section 2.4 only referred to two levels of organization -- the block level and the state level. How far does this extend our effective vision into the future -- the key problem discussed in section 2.3? If the system tends to stay in the same block for k periods of time, then we extend our vision only by a factor of k. Thus the extension of foresight is only like Sutton’s k-step-ahead approach discussed in section 2.3, not like the full kn approach. There are still some advantages over multiresolutional methods, because of the sparsity of matrices here, but the benefit to foresight is more limited.
In order to achieve a kn improvement in foresight, with an event-based architecture, we can extend the designs of the previous section in order to build a multilevel hierarchy. This section will show how to do this, in the example of a three-level hierarchy. In order to extend this result to a hierarchy of more levels, one can simply use the same adaptation rules used here for the middle level, connecting it to the levels immediately above and below, and apply those rules to each one of the middle levels of the larger hierarchy, connecting each of them to the level immediately above and below. This is a straightforward process, but this section will only present the three-level case, simply in order to keep the equations from appearing truly horrendous.
This section will present a decision-making formulation (ala 1.4.3), based on a three-level extension of the simple partition design, with backwards value updates. Other variations discussed in section 2.4 carry over in a straightforward way. (For example, a purely passive block design may be obtained simply by providing only one choice of allowed decision blocks at each postexit state.)
2.5.1 Changes in Notation
This section will use slightly different notation from section 2.4, in order to reduce the complexity of the equations. As before, we will assume a finite number of possible states i or j of the environment. But now, the letters A and B will refer to decision blocks. Decision blocks are essentially made up of states, plus local action policies uiA specifying the actions u to take in each state i of A, an internal critic JiA0, and an interaction critic JijAI . JiA0 is essentially the same as JA of section 2.4, and is defined for all iÎA. JijAI is essentially the same as JAB of section 2.4, and is defined for all iÎA and jÎp(A), where p(A) is the set of all post-exit states of A. The superscript symbols “0” and “I” are chosen by analogy to the symbols H0 and HI in quantum physics, symbols which represent the autonomous versus interactive components of the operator H which governs the dynamics of the universe.
Here we will also consider higher-order decision blocks, a and b. Higher-order decision blocks are made up of decision blocks. Just as the same state, i, may appear in multiple competing decision blocks, so too may the same decision block A appear in multiple competing higher-level decision blocks.
The union of p(A), across all blocks A in a, will be denoted as p(a). The set of all block-post-exit states in the entire system, i.e. the union of p(a) across all higher-order blocks a, may be written as p(). The post-exit states of a itself will be written as P(a). The union of P(a) over all higher-order blocks a will be written as P(). Each higher-order decision block must contain a set of decision blocks, plus an internal critic Jia0 and an interaction critic JijaI. These critics are defined for all iÎa which are also in p(), and for all j in p(a).
In general, for any state i, let d(i) be the set of decision blocks which can be selected from at state i. Let D(i) be the set of higher-order decision blocks which can be selected at state i. In a simple decision scheme (as described in section 2.4.3), D(i) is only defined for iÎP(), and d(i) is defined only for iÎp(); however, the discussion below will also allow for the possibility of allowing a change of minds and unexpected exits (as discussed in 2.4.3).
For the sake of computational efficiency, we will need to implement an additional “critic” for each decision block A, which may be written as JjA+, defined for jÎp(A).
Note how this change in notation simplifies the description of decision-making designs. For example, in this notation, if state i is a state in which a decision is required, in the two-level design of section 2.4, equation 23 becomes:
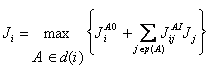 (35)
(35)
If i is a state in which no decision is required, then A should be already specified for that state, and Ji simply equals the term within the curly brackets in equation 35.
Finally, for the sake of generality and readability, we need to replace the awkward notation used for learning used in equations 28, 29 and 33. In each of those equations, an old estimate is replaced by a new estimate, based upon a new example. The precise update rules given in those equations were really just the simplest example of a way to do that kind of learning. More generally, in each of those situations there was an old estimate (or network), which is updated in response to a new desired value or output, which may be called a “target value.” Learning methods or architectures which can perform this kind of task are called supervised learning systems [2]. For the full three-brain system, in the software version, the user will be given a choice of supervised learning systems; the ultimate preferred choice for a supervised learning system [2] will be far more complex than the simple fixed linear learning scheme shown in the previous equations. Thus to indicate a supervised-learning update in a more general fashion, we will use the notation:
estimate ¬ target (36)
For example, equation 29 is replaced by the more general update rule:
JiB(s(t)) ¬ “JjB(s(t+1))”/(1+r) (37)
2.5.2 The
Three-Level Design Itself
The state-by-state update rules for JA0 and JAI, within any decision block A, are essentially the same as in section 2.4, i.e.:
JiA0 ¬ U(i, uiA) + “JA0(s(t+1))”/(1+r), (38)
where “JA0(s(t+1))” is Js(t+1)A0 in the case where s(t+1)ÎA, Js(t+1)B0 in case of an unexpected exit to decision block B, and 0 otherwise; and:
JijAI ¬ “JijAI(s(t+1))”/(1+r) = Js(t+1),jAI /(1+r) (if s(t+1)ÎA)
= 1/(1+r) (if s(t+1) = j) (39)
= Js(t+1),jBI /(1+r) (if s(t+1)ÎB by unexpected exit)
= 0 (otherwise)
When a state i demands that a decision be made, these updates are inapplicable until after the appropriate data block has been chosen. Updates are made only for the chosen decision block, not for other blocks containing a state. For a simple decision-making scheme, as discussed in section 2.4.3, unexpected exit modes do not occur; however, for the general case, one must allow for their possibility.
When a state i requires that a higher-level decision be made, that decision should be made first before any lower-level decision is made in that state. The higher-level decision is made based upon the relation:
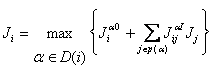 (40)
(40)
After this higher-level decision is made (based on this maximization), we update Ji so as to match the target value of the right-hand side of this equation, which yields a backwards value update. (Actually, as in equation 32, a forwards value update could be used instead, but would not appear to be preferable in most cases.)
When a state i requires that a decision be made, and when state i is already in a definite higher-order decision block a, the decision is made based on:
 (41)
(41)
For strict accuracy, we may first update each of the JjA+ values used in equation 41, for jÎa, by using the equation:
![]() (42)
(42)
(However, to reduce calculations, we may maintain flags or recency factors on each of the J+ values, and perform this calculation only when the flags indicate that an update is overdue.) After the decision has been made (i.e., after a block A has been selected for state i), then two further updates should be carried out
if iÎp():
![]() , (43)
, (43)
where “Jja0” is Jja0 if jÎA, or 0 otherwise; and:
![]() , (44)
, (44)
where “JjkaI” is JjkaI if jÎA, or 1 if j=k, or 0 otherwise. Similar to equations 38 and 39, the terms in quotations in equations 43 and 44 are replaced by Jjb0 or JjkbI, respectively, if jÎb as the result of an unexpected exit from the higher order block a. (Again, recall from section 2.4.3 that unexpected exits do not represent “failure,” if failure corresponds to one of the possible, anticipated but not desired states. These special provisions apply to exits which were not even considered on this list of possibilities p(a).)
After the decision has been made in state i, we also have the option of performing a third update:
![]() (45)
(45)
Again, these updates are generally backwards value updates, as discussed in section 2.4.2; the forwards equivalents are generally straightforward, by analogy to that section.
Finally, in order to complete the basic design, we must specify how to pick the actions u at any time i, after the relevant decision A and higher-level decision a have been made. In this case, we simply choose u(i) so as to maximize:
![]() , (46)
, (46)
where:
 (47)
(47)
Recall, from section 2.3, that all of these equations and the corresponding designs are simplified substantially in the special case where the utility function U is a growth process.
2.5.3 Action
Networks, Decision Networks and
Other Extensions of the Design
As previously mentioned, the various variants mentioned in section 2.4, like the focused partition design, can also be applied here in a straightforward manner.
In addition, it is straightforward to modify this system to permit the use of trees of decision blocks or task modules of varying depth. For example, one can define a “higher level” block a which contains only one decision block A. In effect, then, a becomes a kind of alias for A. In this way, we can design still-higher-level decision blocks for which, in some states i, one has a choice between initiating a truly high-level task b (a higher-level decision block) or lower-level task (A, appearing under the alias of a). The design above still goes through, without significant computational overhead involved in the “aliasing.” Using this procedure, it is then straightforward to handle this more general form of hierarchy of tasks or decision modules.
The most important extensions are those which lay the groundwork for the use of neural networks, to be discussed in section 3. Of these extensions, the most important is the use of action networks and/or decision networks instead of optimal actions and decisions.
In the simplest designs -- as above -- we always choose the best possible action u in any state i, the best possible decision A when there is a decision to be made, and the best possible higher-level decision a. This always gives the optimal result. When the number of choices is discrete and few, it is a reasonable way to go. However, when the number of choices is large, the computational cost of finding the true optimum in all cases becomes unrealistic. In that case, we can build some sort of network -- deterministic or stochastic -- to output actions or decisions as a function of the state and of other information.
There is a wide variety of such “action network” designs available in the adaptive critic literature[2,8], all of which can be applied here in a straightforward way, both to actions and to decisions. In addition, one can build action or decision networks which simulate several alternative possibilities at each time, and then: (1) select the best of the few; (2) adapt the network, based on these results.A slight variation of this is to maintain a buffer containing the “best action/decision possibility found so far,” and to update the buffer only when the stochastic action/decision network finds something better for the current state. Section 4 will discuss some new possibilities for implementing these subsystems, which are part of the preferred embodiment of the full neural 3-brain architecture. All of these adaptive designs also require some choice between the many, many possibilities available [2,8] for initializing the various networks.
Once we extend the design by using action networks and decision networks, we can go one step further by allowing modifiers to decisions. Intuitively, then, we may think of the decision choices as something like subroutines or verbs. The modifiers are something like input arguments or adverbs. (Objects will not be discussed until a later section.) Given a decision block A, we may specify
an associated vector, uA, which contains the adverbs.
The adverbs may be discrete or continuous or a combination of both. There are two major kinds of adverbs, passive and active. For passive adverbs, the postexit states are still a function p(A) of A alone. For active adverbs, they depend on the adverbs; in other words, we have p(A,uA).
The extension to passive adverbs is fairly easy, in principle. We expect that the decision block will be initialized to allow for some variation in its actions depending on uA. We set up the action network, the internal critic network, and the interconnection critic network to receive uA as part of their input vectors. We set up the decision network to output first A and then uA. (The obvious way to structure this is to add an adverb-generating network which outputs uA whenever A has just been decided upon.) Then we train the various networks just as we normally would do.
For the full version of the system, we would expect a combination both of passive adverbs and of active adverbs. With active adverbs, it is no longer practical to implement the various calculations above which require explicit consideration of all possible decisions, because the choice of adverbs allows many possible decisions, in effect. (Mathematically, the equations above then remain valid, but with “decision” replaced by “combination of decision and active adverb”.) Again, however, the use of decision networks instead of exact optimization leads to a straightforward approximation of the equations above.
The choice of words “verb” and “adverb” is not just an analogy here. Our speculation is that these sorts of computational structures, as implemented in the mammalian brain, do provide the deep structure which underlies the way we talk about our lives in human language.
2.5.4 Learning of the Underlying Partitions
The previous discussion has assumed a fixed, known partition of the set of possible states. In other words, the sets of states labeled A, a, etc., are all assumed to be known.
For tasks which truly involve a finite list of possible states, this is a reasonable assumption. There is a large body of methods already in existence on sparse matrices and domain decomposition techniques; thus, if useful partitions of the matrix P are not obvious by inspection, we can simply borrow methods from that well-established literature to find them. The case where P(P) depends on P can be addressed as an extension of these methods.
On the other hand, for a truly brain-like intelligent control system, one would prefer to augment such initial techniques by adding a learning capability, which can adjust the partitions based on learning, either real-time learning or off-line learning [2]. This becomes more important for the neural network extension/approximation of this design, to be described in section 3. However, the approaches to be described in that section can be seen as extensions (roughly) of approaches which can be used even in the case where there is a finite list of possible states.
The most important requirement, to permit learning, is to carry out some re-evaluation of decisions in mid-stream, on some sort of random or regular or event-driven basis. (As with many of the adaptation methods in the adaptive critic literature [8], one can use -- in theory -- “almost any” sampling strategy which is mixed and diverse enough to eventually touch base with all relevant states. Measures of new opportunity or of surprise could be used, for example, to trigger higher probabilities of reconsideration, above a lower but nonzero baseline probability which always applies.)
When such reconsideration is allowed, one can keep track of the unexpected exit states for each block A, and, when certain unexpected exit states are both frequent and important, add them to the set p(A). Likewise, one can prune the set p(A) by deleting states which are rare or unimportant, as measured, again, by the statistical experience of the system. Whenever a state outside of A frequently exits into A, one can add that state to A, on a trial basis, even though this would permit an overlap with a previous decision block. Section 2.4.3 has mentioned some additional adjustment rules which would also be added, to construct a full 3-brain system.
In some previous work [1], it was speculated that a true, flexible learning of partitions in the neural network version would require the use of fuzzy partitions, in which crisp sets like A and a are replaced by fuzzy sets. Based on the more detailed design work of the past year, this no longer seems to be the case, for two main reasons: (1) decision blocks, unlike the passive blocks of section 2.4, can be overlapping sets anyway, which opens the door to the procedures of the previous paragraph; (2) the key to the optimal adaptation of a decision block is to know when the intelligent system is committed to a particular decision. Because each individual decision block can normally find the local optimum “within its own domain,” and because the choice between decision blocks is essentially a discrete choice rather than the incremental kind of choice where compromise methods are useful, the value of fuzzy partitions now seems questionable here. Thus the preferred 3-brain design to be given in section 3 will be an extension of the design here in section 2.5. However, for the sake of generality, the principles necessary to creating a fuzzy extension of this design will be described in section 2.6.
Note that in section 3, it will not be necessary for the neural network system to know the sets A or p(A) as such. It will be good enough to know which decision is in effect at any time, and to know when there is a transition from one decision block to another.
2.6 Fuzzy Partitions:
A Possible Extension of the Design
Equation 10 may be written in slightly different form as:
![]() (48)
(48)
Starting from this equation, we may choose any array bij and derive the following equation by substitution:
![]()
(49a)
![]() ,
,
where:
![]() (49b)
(49b)
![]() (49c)
(49c)
This equation looks very similar, at first, to some equations proposed by Sutton in [6]. However, there are several differences which are crucial and not obvious. First, instead of assuming an array bij, he assumed only a vector of values bi, for any given “abstract action.” Adding a dependence on j is crucial, for reasons to be discussed. Second, while Sutton did discuss the idea that a given weight vector b might be associated with a particular “abstract action,” he did not describe any procedure for choosing different abstract actions or decisions at different states; in effect, he only considered the problem of choosing a single abstract action or policy to be applied to all states. The generalization to our situation is not trivial, since it requires consideration of how to handle the transitions from one decision block to another, which is central to the discussion above.
When Sutton’s discussion is assimilated into our context, he seems to be suggesting that bi should be set equal to the degree of membership mi of a given state i in a given decision block. However, his equations then show value weights converging to zero over time, when the state of the system merely stays put in a fixed state which has a membership value less than one! This is radically different from the kind of behavior we have seen and sought in sections 2.4 and 2.5! When we use a bij array, we then have two other obvious possibilities: (1) the preferred possibility, to set bij to m(j)/m(i) (in the case where this is less than 1, or 1 if not); (2) to set bij to 1+m(j)-m(i) (again limited to a maximum of 1.).
When our preferred version is used on the problem in section 2.4, in the limit where m is always 1 or 0, it reproduces the equations of 2.4 (and their extensions in 2.5), with only the minor point that it allows the calculation of internal critics for states which extend beyond the entry to the block. (These can be simply thrown out as unnecessary calculations.) In the general case, we get back essentially the same adaptation rules as in section 2.5.2, except that the discrete choice of alternative targets is replaced by weighted sums which depend on the change in the membership function from time t to t+1. This follows from simple substitution of equation 49 into the derivations. The details are not shown here, however, because this extension is not the preferred embodiment of the 3-brain approach.
3 Temporal Chunking With Neural Networks
3.1 Goals
The purpose of this section is to describe how to build an intelligent system using neural networks (or other similar learning components [2]) to perform optimization over time, using a learning-based approximation of the structure in section 2.5.2, with the associated methods already discussed in section 2.
In a formal sense, the details in section 2 are strictly precise even for the most general range of tasks. (Even when a task involves continuous variables, the system normally can be approximated to any desired degree of accuracy using a large but finite number of states, in principle, if one is careful.)
The purpose of building a neural network system to approximate section 2.5.2 is toe reduce the number of calculations needed, particularly in the case where there are many continuous variables present in the external environment or the plant to be controlled; this reduction, in turn, makes it possible for the resulting intelligent system to cope effectively (though approximately) with a larger variety of more complex tasks, within the limits of what is computationally feasible. By using neural network approximation methods, instead of other learning-based approximators, we can extend the range of what is computationally feasible because we can use special-purpose hardware dedicated to implementing these particular architectures.
Many aspects of how to approximate dynamic programming with neural networks have already been established in the literature [1,2,8] and in a previous patent disclosure by this inventor. For example, the methods called HDP, DHP and GDHP have all been defined in great detail as methods of approximating the original Bellman equation; for the modified Bellman equations, as expressed in sections 2.4 and 2.5, the corresponding changes in these 3 methods follow in a straightforward way. This novel combination is a major part of this disclosure.
On the other hand, certain aspects of the neural network extension are much more difficult. This section will describe the overall structure of the new architecture, emphasizing the critical novel details necessary to make it work.
This section will mainly address the issue of temporal chunking -- i.e., the design of a system aimed at solving problems where partitions over time are very useful, but there are no special assumptions made about the structure of space, or even about decomposition between different groups of variables at the same time. For a full brain-like structure, such issues of spatial chunking must also be exploited. This section will occasionally mention design details aimed at exploiting spatial chunking; however, the main discussion of such further design extensions will be postponed until section 4.
3.2 Overall Structure of the System
First of all, we will assume that the intelligent system is made up of a multilevel hierarchy of decision blocks, as in section 2.5. As in section 2.5, a particular decision block may have “aliases” at higher levels. The highest level of all is not a decision block, but a kind of global critic network (or J estimator), again as in section 2.5. Thus by specifying the learning and dynamics within a general mid-level decision block (as in section 2.5), we essentially specify the entire system.

Figure 1. Structure of a Decision Block
In effect, each level or stratum of the hierarchy contains a discrete “library” of decision blocks. The main goal of this section is to describe how individual decision blocks are adapted over time. This is analogous to the usual adaptation schemes used to adapt individual weights in simple artificial neural networks (ANNs). As with the simple ANNs, however, there is a huge variety of useful but semi-arbitrary tricks which one can use to “grow” or “prune” the overall system. For example, if one frequently uses a given block with different arguments, one may create a “copy” of that block at the same level of the hierarchy, which then permits separate adaptation of the two, as a way of “growing” the repertoire of modules. Blocks which are rarely used can be deleted. Blocks which are frequently used in sequence can be merged (in one step or partial steps) into a larger block, even without deleting the original two blocks. (In fact, the creation of such a new block could explain the experiments on “insight” described by Brooks [9].)
Biologically, the levels of this hierarchy are assumed to correspond to the various “loops” (low-level and high-level) in the circuits through the basal ganglia described by Brooks [9] and others. It now appears that a system of only 7 or 8 such levels could replicate the kind of capabilities one observes in the mammalian brain.
In biological systems, the execution of decision modules is not always sequential, even at the higher levels of intelligence that we are trying to reproduce here. At times, certain actions -- like walking and talking -- can be carried out concurrently. This may require a kind of spatial decomposition of the environment. In effect, it may require an extension of the purely temporal design which will be the main (though not exclusive) focus of this section. This kind of simultaneous commitment to different actions is not an example of fuzzy commitment (section 2.6), because of the issues raised in section 2.5. There is a very powerful system of lateral inhibition in the state of the basal ganglia, which ensures that discrete choices (of a go/no-go variety) are made between competing possible decisions, under normal circumstances [9]. There is a kind of fuzziness or uncertainty in the values (critic estimates) which underlie the decisions made at any time; however, in some sense, the system can really focus only on one goal at a time. It may waver between competing goals, however. It should also be noted that mammals -- unlike large-scale factories -- are extended more in time than they are in space; thus aspects of spatial chunking which are useful in factory control may not always be relevant to mammalian intelligence.
In the discussion which follows, it will generally be assumed that each decision block is made up of independent neural networks “inside” each block, sharing access to some global set of feature variables {ri} available to all modules. In practice, it is also possible -- as in the brain -- to share many “hidden neurons” between blocks. It is also possible to use growing and pruning schemes which tend to give preference to the use of “neighboring” variables, and so on, as has been done or proposed before for simpler ANNs. For simplicity, however, the discussion below will treat the various decision blocks as if they were made up of independent networks. Also, the discussion below will refer throughout to “neural networks;” however, as discussed in [2], this should be understood as a shorthand term for “ANNs or other learning structures which perform similar tasks, such as supervised learning, etc.”
3.3 Structure and Training of a Decision Block
Within each decision block, we will first need neural networks to approximate the JA0 and JAI terms in equation 41. For JA0, the obvious procedure is to train a neural network using supervised learning, based on equation 38. More precisely, one would insert a neural network to receive as inputs i, A, and uA, and train it to match the targets given in equation 38. Instead of an integer “i,” one would use r, the current estimated state vector of the environment, learned primarily through neuroidentification techniques [2]. For JAI, however, the situation is much trickier. Ideally -- in order to approximate the value updates indicated in equations 41-44 -- one might want to build a network which inputs r, A, uA and JjA+, and again to train it to match the targets implied by equation 39.
However, for a true neural network approximation, we cannot assume the availability of the full vector JjA+ !! The vector JjA+ includes values for every possible outcome state of the decision block! This is a central problem. Somehow, the vector JjA+ must be summarized or compressed into the lower-dimensional kind of vector which is suitable for a true neural network system. Such a compressed vector representation will be described as SIA+ . Note that this vector summarizes JjA+ across all states j in p(A). The letters “SI” stand for “Strategic Information.”
In general, the SI vectors can be generated as the output of a decision network (which, by itself, would make them really the same as the uA vectors described previously), or as a kind of communication which passes back value information explicitly from one decision block to a previous decision block. However, if each block develops its own compression scheme, it becomes extremely difficult to develop translation networks from each possible decision block to each other block which may precede it!
As an alternative, for the 3-brain architecture, we will implement the SI vectors as Quadratic SI (QSI) vectors. In fact, each QSI “vector” will actually be a “goal object” or “fuzzy image,” consisting of two scalars -- g0 and g1 -- and two vectors, r* and w. A goal object g will represent the value or critic function:
![]() , (50)
, (50)
where ri is one of the global feature or state variables. (As a practical matter, of course, individual decision blocks may “nominate” new features that they need to the global array, or, more easily, may influence the development of new features indirectly through backpropagation feedback they send back to the r network -- something which happens automatically in a full implementation of the appropriate backpropagation learning.)
For a fully active design (as defined in section 2.4.3), we must account for the fact that action policies change as a result of values received from outside. Thus the JA) network, like the JAI network, will be assumed to input r, A, uA and gA+, where gA+ is a goal object input to the decision block. (Because gA+ is still a vector made up of a fixed number of components, to the same extent that r is, we can still just insert it as an additional input to a standard supervised learning system.) One can then use the targets as described in equations 38 and 39, and train the action network (or lower level decision network) exactly as in section 2.5. In theory, we could certainly merge the two networks into one network, trained to match the sum of the two targets; however, this is not the preferred variant of the method, because it loses some information .
In order to complete this design, however, we also need to include some additional components, some essential and some (though optional) part of the preferred variation.
First of all, in order to permit the backwards flow of goal information, g, we need to create a new network, JA-, in each decision block, with the following characteristics. JA- will contain one or more “components” (blocks of hidden units) giA-; at any given time, we allow i=1 to nA-, for a fixed number nA-, which may be grown or pruned. Whenever the decision block A is chosen, and the rest of the decision made, in a state r, the network JA- may be trained. JA- inputs the state r and the set of goal objects giA-. The goal objects giA-, in turn, input the state r, the goal object gA+, and uA, plus some additional information to be described below. Both JA- and the hidden component networks giA- are trained (either by backpropagation or some other supervised learning method able to adapt such hidden layers) in order to match JA0(r)+JAI(r). This provides a kind of compression technique, similar to the “bottleneck” approach used in encoder/decoder designs or in the SEDP design [8, chapter 13]. One way to implement this approach is to train classic Gaussian-like neural networks (such as radial basis functions, PNNs, or Kohonen networks) to try to predict JA0(r)+JAI(r) in the actual entry states r., and use a more general neural network, in effect, to predict the reamining erreor; in that case, the JA- network is the sum of the Gaussian network (which would use only a small number of prototypes) and the more general networks. In such training, it is important that the entry states r be sampled in a way which represents actual desired operation, rather than some kind of uniform sampling across large ranges of states which are not likely to be visited.
Secondly, in order to improve the training of the system, it is preferred that each decision block also contain a network JA+, which is trained to estimate J in the p(A) states. (In theory, JAI could take over this function, but there are potential benefits to learning in decomposing qualitatively different learning tasks.) Thus in training the JAI network, whenever s(t+1) is in p(A) (i.e. when a new decision block is invoked -- an explicit representation of p(A) is unnecessary), we can use JA+, in effect, as the target. Likewise, we can use the output of this JA+ network in evaluating possible simulated results jÎp(A) of choosing decision A in an initial state i. Note the importance of training JA+ to match JB0+JBI for the resulting state j, after the subsequent decision B is known; by training to that information, instead of training directly to a fuzzy goal image, one can improve robustness considerably.
For completeness, JA+ and the previously mentioned networks should all receive an additional set of inputs. These would represent ga+ and ua and a, where a is the larger decision block in which A is embedded, as well as similar information for the blocks in which a is embedded, and so on. This is a large amount of information. For parsimony, however, one can “channel” this information,
by defining a compression network either for all of a or for A in particular. This compression network would receive the three mentioned sources of input, plus r, plus the output of the compression network of the next higher block. It would output information then used as “hidden units” in the various networks associated with block A, trained based on feedback from all those networks. There are other similar methods of compression which could be used instead, but this at least shows that it can be done without too much difficulty. This compression network is providing information about the larger strategic context which could be important in some cases.
Thirdly, the operations described above -- including the use of forwards results sampling in order to evaluate possible decisions and to train decision networks -- clearly require the existence of a network to predict or simulate an outcome state “j”Îp(A) based on an entry state r, A, uA and gA+ and larger strategic information. In effect, the network to perform such simulations would really be a network representation of (JAI)T, the matrix of (discounted) transition probabilities! To build such a stochastic simulation network, one could either use crude conventional neuroidentification techniques [2], or insert a full-fledged stochastic prediction network like SEDP [8,chapter 13] or SOM[10]. (In act, one could build an extension of SEDP, using SOM principles, so that instead of outputting just one estimated R vector, it outputs a discrete set of such R vectors, representing different discrete clusters of possible outcomes. In effect, our JA- network is essentially just a transpose of this; one could also try to unify these two dual network approaches. The R-based probability descriptions generated by SEDP can be thought of as another kind of “fuzzy image,” dual to the goal objects.) The use of a truly stochastic simulation component is an essential part of the full architecture, because it is difficult to make useful deterministic forecasts over long periods of time in many strategic situations; for example, a “best guess” forecast of the probability of a white stone being on a given square, in a game of Go, looking ahead 40 moves, would be a fairly useless tool in strategic planning in that game. Stochastic designs like SEDP, by contrast, do account for correlation between different variables (like different squares), and develop representations of higher-level strategic patterns which may be more persistent and interesting over longer time intervals.
Finally, in order to complete this arrangement, we need to have a mechanism available which actually allows us to make decisions at a state “i” (or r) before we know for sure what the resulting state jÎp(A) and the follow-up decision will be. To do this, we need to develop a goal network, gA+ (or a unified goal network applicable to all states within a). This network would input the same information as JA+ does, except of course for itself. It would be trained by supervised learning, in order to match the goals gB- which are later developed by the following decision block, after the following decision is known. Of course, this kind of training can be used on “simulated” or “imagined” states, as with ordinary critic learning. If nB->1, the goal which yields the highest evaluation of the result state j is used.
Actually, there are good reasons to weight this supervised learning, to try to match gA+ to gB- more energetically in some situations that in others. Higher weights should be given in cases of success, such as cases when JB0+JBI is higher in the result state j than might have been expected. (A variety of similar metrics could be used.) The exact function used to determine the weight of each observation as a function of success is arbitrary, in principle; as with the arbitrary choice of certain parameters in any learning system, it provides a legitimate basis for variation from one learning system to another, leading to variations in “cognitive style” or “personality,” all of which are workable but which vary in effectiveness from environment to environment.
For the effective operation of this system, there are two important subsystem issues which need to be considered explicitly.
First, because the time chunks here (from entry to exit of a block) are usually much larger than one computing cycle, the system will work best if there is frequent “arbitrary” simulation or exploration of possible interesting states in the near future. This is also true (though to a lesser extent) in ordinary adaptive critic adaptation[8], where a wide variety of simulation or exploration approaches have been tried -- all valid in theory, but very variable in practice. Clearly this design includes both “backwards chaining” (using JA- to find “subgoals” related to a goal gA+) and “forward chaining” (future simulation, perhaps using a supplementary decision network to suggest possible alternative goals gA+ instead of just possible A and uA.)
Second, it is critical, in practice to be aware here of the availability of supervised learning systems which learn very rapidly through some kind of local learning or associative memory, and of “syncretism” approaches [8, chapter 3] which permit further generalization from there. In practice, if the gA+ network effectively “remembers” the results of forwards and backwards chaining in the current instance of block a, under current circumstances, this type of design -- properly implemented -- should be able to fully replicate the capabilities of mixed forward-chaining backwards-chaining reasoning systems used in planning in traditional artificial intelligence.
3.4 Possible Variations of This Architecture
There are a number of possible variations of this design, of varying usefulness. In addition to the variations mentioned in previous sections, there are the following variations of increasing relevance here:
(1) Using only uA, not g.
(2) Allowing multiple goals gA+ in decision blocks.
(3) Multiplexing the processing of goals at different levels.
(4) Symbolic communication between modules.
(5) Linear SI vectors.
(6) Spatial "convolution" of goals.
Of these six, the first four are not part of the preferred embodiment, the fifth is of marginal interest, and only the sixth is part of the 3-brain architecture proposed here. The sixth anticipates some further extensions to be discussed in section 4.
First of all, the design of the previous section would clearly be radically simplified if goal objects g were not used. To some extent, modifiers uA can take over some of the same functions, of defining the goals to be pursued in a particular task invocation. In early implementations of our approach, this variation will be extremely useful because of its simplicity. In the long-term, however, the lack of rapid electronic transmission of J+ information, in effect, makes this a more passive, less modular approach than our baseline architecture. It is also less plausible than the base architecture as a description of mammalian thought, in which the inherent ability to focus on a goal is clearly very fundamental. In section 3.3, the opposite simplification was briefly mentioned -- the possibility of using goals g in place of scalar critic networks J, in some situations; that simplification would lead to excessive rigidity or robotic character in decision-making, not allowing at all for the robustness of adjusting evaluations so as to account for values which are not entirely translated into specific goals. This corresponds to our natural observation, as human beings, that we can reason very quickly about explicit goals, but that we still need to adjust the resulting conclusions so as to account for "subconscious" feelings, impressions and intuitions which lie beyond the explicitly stated goals.
Secondly, it would seem extremely natural and fairly straightforward to extend this framework to permit multiple goals or outcomes. For example, if a hybrid SEDP/SOM simulation model were trained, within each decision block, it would lead to a very natural way of partitioning p(A), in effect. One could simply use the general g+ network to fill in all of the multiple goals of a decision block, except when exploring particular outcome states, where we could modify only the g+ applying to that state. However, this kind of design would lead to a great deal of additional complexity. As an alternative, in situations where there are a small number of desirable alternative outcomes, one could usually just split the block up into separate blocks, one for each goal. After all, in the pure temporal chunking situation, these different goals are not mutually consistent anyway. When there is a mix of desirable and undesirable outcome possibilities, it is usually enough to focus on the desired outcome (for higher-level planning purposes) and
let the decision block learn to reduce the probability of the others to zero. When humans are confronted with multiple attractors, it seems more plausible that they waver between these attractors (or focus on a more abstract goal definition), rather than focus on multiple competing targets. Nevertheless, the multiple goal option is just viable enough that it should be rejected completely at this stage.
Thirdly, when we implement the 3brain architecture on computer hardware, the obvious approach for now is to implement each stratum in parallel, so that each uses its own computational resources as efficiently as possible in making the decisions at its level. Presumably, then, the higher levels would "imagine" more distant future possibilities, etc. In practice, however, if there are 7 strata, there could be a seven-fold saving in hardware if one could somehow multiplex these calculations through a single, unified network system. The resulting complexity is probably not worth the cost, at the present state of the art, but it may be useful eventually. In fact, an introspective view of human thought, imagination and dreaming suggests that such a multiplexed, one-idea-at-a-time approach is probably used in the actual mammalian brain.
Fourth, the communication between decision modules could be made far more complex than a simple fuzzy goal image, g, even without imposing the requirement of complex translation networks. In theory, for example, a decision module A could output, instead of gA-, an explicit, structured verbal/symbolic description of the current value function JA0+JAI for the entry states of A. If the preceding decision module B could truly understand symbolic representations, then it could use such a representation directly, and analyze it in very complex detail. Many readers will immediately notice that this sounds more like a society of intelligent, symbolic reasoning units -- like a human society -- rather than a collection of neurons. It is extremely unlikely that simple task modules in the mammalian brain can communicate with each other in this way, since even whole mammals (except humans) cannot do as much! Furthermore, because of conflicts of goals, human societies certainly do not prove that such a "multimodular" level of intelligence -- far beyond the mammalian level -- is really possible. Perhaps it will be possible, someday, to build a unified intelligence on this basis, well beyond the human level of intelligence. However, that is both unproven, and beyond the scope of what is proposed here.
Fifth, on a more mundane level, there is a very sensible-looking alternative to the QSI: the Linear SI vector, which consists only of a scalar v0 and a vector v, representing:
![]() (51)
(51)
The LSI approach is not a viable alternative to QSI, because it cannot represent the wide variety in concrete goal states needed for a flexible planning system. However, it is very plausible to consider adding an LSI object to the QSI objects, to provide additional guidance to a decision block based on future expectations. For example, one can imagine trying to walk to a desired location (goal), while placing extra weight on trying to avoid places where rain comes down on your head; this weight may depend on special current information. It is not clear that the additional complexity of allowing such an input would be worth the trouble; however, it may be worth considering as an extension, after the baseline system is more fully tested.
Finally, in the design of JA- networks, it is important to train the goal subnetworks (especially per the growing and pruning aspects of learning) so as to preserve the elements (ri*,wi) of gA+ which decision A has little effect on. The practical effect of this is to make gA- into a kind of convolution of gA+ and of the effect of A. This, in turn, is crucial to the effectiveness of this system in handling tasks where the various variables ri actually represent different regions in space, or even when they simply form groups of variables that do not interact so strongly with each other.
4 Spatial Chunking and
Critical Subsystems
4.1 Summary: Spatial
Chunking in General, and Combinatorial Optimization
The previous section describes a generalized neural network based intelligent system, to exploit the power of temporal chunking. However, as Albus [7] and others have stressed, the world of our experience also permits a certain degree of "spatial chunking." Spatial effects do appear to be very critical in major parts of the mammalian brain, such as the hippocampus.
This section will suggest that most of the power of exploiting spatial effects can be obtained within the design of section 3, so long as the subsystems used in that design are properly chosen. However, as noted in section 3, the main goal here is to replicate the level of intelligence seen in mammals, who are not so extended in space (at any time) as they are in time.
The simplest form of spatial effect is the concurrent invocation of parallel decision blocks, affecting different kinds of actions. One way to achieve such capabilities is as follows. When there is a decision block currently activated, and a part of the goal which involves other variables not affected by the current decision block (as should be evident from the structure of the JA- network), then one can define a new decision block as the combination of the first block and another block which addresses those other goal components. Note that this is simply one more "arbitrary" rule to be added to the growing(/pruning) system for decision blocks, similar in flavor to the "insight" rule mentioned in section 3. One can the invoke that two-things-at-a-time activity -- and either fine-tune it or discard it. No fundamental changes in the underlying design are needed to add this kind of capability. This additional capability is part of the fullest, mammal-like version of the 3brain architecture.
A second, more fundamental aspect of space is the exploitation of spatial symmetry. Two of the papers included here by reference (Werbos and Pang[12], and Pang and Werbos[13]) describe how Euclidean spatial symmetry can be incorporated into a supervised learning system, which in turn could be used as the critic network of a larger intelligent system. In a similar vein, all of the various neural networks described in the previous section could be implemented as neural networks embodying symmetry principles. For Euclidean symmetry, we could simply use the kind of symmetry in the incorporated papers. But for nonEuclidean symmetry, we must use a further variation, to be described in section 4.2.
A third important aspect of space is true spatial chunking. As an example, John Holland has noted how a roadmap serves as a spatially chunked (simplified) representation of the more detailed pictures one might see from a satellite. This kind of spatial chunking is really nothing more than a compression of information across space. One can achieve this kind of compression by using the compression method, SEDP [8, chapter 13], with component networks that move across a spatial (Euclidean or nonEuclidean) "window," using the principles of section 4.2.
Finally, a fourth aspect of space is something which may be called the "big world problem." For example, Albus [7] has pointed out that the usual sort of estimated state vector one derives in engineering may really be just a small window into the larger physical environment of a mobile intelligent system, an environment which is mostly far outside the sight of the system. He argues that the system must maintain both an estimated state vector, r, in effect, and also a larger "world model" in which the current r is attached to only one site or node. This is a very persuasive perspective, but this disclosure will not provide a specific technique for addressing it. There is a very deep problem in the "big world" view, in trying to describe how a creature may predict the near-term future of large areas that he has no data on at all, except by simply using the spatially symmetric forecasting tools implied by the previous paragraph.
Most of the subsystems required in section 3 already exist -- in many forms and many variations -- in the neural network literature and elsewhere. The new papers incorporated here (and section 4.2) provide some basis for improving the subsystems, and thereby improving the overall behavior of the system, but the previous neural networks provide at least some basis for an early implementation. The main exception to this concerns the training of adaptive decision networks, networks to make both continuous and discrete decisions, so as to maximize a rather complex function of these decisions. Section 4.3. will describe some new designs to fill in that gap.
Finally, all these various component neural networks -- whether spatially symmetric or not -- are ultimately composed mainly of function approximation networks, as discussed in [2]. For an efficient hardware implementation of these systems, the most important aspect is to implement this computation-intensive "inner loop" -- the function approximation networks at the core of the system. At the present time, perhaps the greatest computational throughput of any general-purpose computing system (both today and as expected in 10-20 years) comes from the 3DANN (3-Dimensional ANN) hardware being developed by the Jet Propulsion Laboratory. The 3DANN system is not implementing SRN components, as described in the incorporated papers. However, for SRN networks implemented as a core feedforward network of a single layer (which can always represent the equivalent of one implemented around a multilayer network), it would require a relatively straightforward modification of the 3DANN hardware to implement them. With cellular SRNs, where the connections are more limited, the implementation would be far more compact, using the same approach to hardware design. This is the preferred embodiment of the 3-brain architecture -- i.e. a system of coupled SRNs, coupled according to the higher-level connections implied above, implemented in modified 3DANN-style hardware.
4.2 Symmetry-Based Networks, Euclidean and nonEuclidean
The papers incorporated here by Werbos and Pang[12], and by Pang and Werbos[13], display how to build a Euclidean-symmetric network which inputs an array of spatially-located data, and also outputs an array of spatially located outputs (to match a spatially located array of targets).
There is a straightforward but novel generalization of that design to allow any mixture of spatially located outputs (or targets) and global, nonspatial outputs (or targets). One builds a network with two parts: (1) a "lower" part which is just like the simple spatial-to-spatial network of the incorporated papers (or some other simple spatial-to-spatial design incorporating Euclidean symmetry); and (2) an "upper" part which is a nonspatial (ordinary) network whose inputs may consist of some nonspatial inputs, and up to n special additional inputs, where "n" is the number of neurons in each "cell" of the lower part. Each of these special inputs would represent the sum of the outputs of the corresponding neurons in each of the cells, summed across the cells. (Actually, the number of cells can also be added as an input, when it is expected to vary.) To train this kind of two-level structure, one can still use generalized backpropagation directly. (See [8,ch.10] or the incorporated papers.) This structure directly reflects the principle of Euclidean Lie group symmetry, discussed in the incorporated papers. It is somewhat interesting that the relation between the amygdala and the hippocampus in the mammalian brain looks somewhat similar to this kind of two-layer arrangement, in which the lower layer is sensitive to spatial encoding.
In the example of the maze, discussed in the incorporated papers, the Euclidean design can be interpreted as the repeated use of the same core "cell" of 5 neurons over and over again, in different locations, with input from the cell itself and from each of its four neighbors. One disadvantage of this design is that it requires input from four neighbors even for edge cells, which do not really have four neighbors.
An alternative spatial-to-spatial design -- the nonEuclidean approach -- would be essentially the same in this case, except that the cells can be sorted into three types -- four-neighbor cells, three-neighbor cells, and two-neighbor cells. Instead of reusing one core network in all cells, we can adapt three different core networks, for use on the three different types of cells. The resulting feedforward network is clearly well-defined -- for each cell, we simply use the relevant core network to generate its outputs, and then combine them all to generate the entire array. The resulting SRN wrapped around this feedforward network would simply be defined relative to the feedforward network, as in the incorporated papers. Adaptation can again be done by use of generalized backpropagation, as previously mentioned. Then, to add a global layer on top of this spatial-to-spatial structure, one again transfers inputs based on adding up outputs of corresponding cells in similar objects -- otherwise exactly following the second paragraph of this section.
In general, the nonEuclidean approach can be applied to any complex network of nodes, where "space" refers to nodes in a network rather than coordinates in a regular grid. One can again identify objects with similar relations to other objects, applying a the same core model to all similar objects.
(One can use an extremely loose concept of similarity, and let the core model itself learn what distinctions it must pay attention to.) When objects are connected to complex relations, there are two further variations here: (1) to treat the relations themselves as a type of object; (2) to force equal weights for multiple instances of the same relation out of any object (thereby eliminating the need to worry about how many instances there are.). These choices are like the choices of connections in ordinary ANN training -- choices to be optimized on the basis of incremental error-based learning -- growing, pruning, etc.
Note, as an example, that an SRN structure built on this kind of object-oriented network, with a global classification network on top of it, might be an excellent structure to input structures or maps like representations of chemical molecules, and output predictions of their global properties. It is speculated that the mammalian brain operates mainly on the basis of nonEuclidean symmetry, object-oriented symmetry.
This concept of nonEuclidean or object-oriented symmetry may be interpreted as the neural network extension/version of what statisticians call pooled time-series cross-sectional modeling.
The
concept of object-oriented symmetry in neural nets is not 100% new. The idea
was first conceived by this inventor several years ago, when analyzing problems
of forecasting stocks. By building a general network, to be trained over
several actual stocks, analogous to pooled cross-sectional time-serioes
analysis, it was clear that a major imporvement in accuracy could be acheived.
This combination of ideas from econometrics and neural networks was quite
novel, in part because few reserachers work at the state of the art in both
fields. In 1996, in
4.3 ANNs for Combinatorial
Optimization (Decision Networks)
Even in conventional adaptive critic designs, there are severe limitations in the capabilities of existing "action networks" and in the methods used to train them. The decision networks discussed in section 3 perform essentially the same task as these conventional action networks, but -- because they are intended for use in demanding, complex applications -- the need for improved capability becomes essential.
In general, the problem here is to build and train a network which outputs an action or decision vector u, composed of both discrete and continuous components. For each observation of inputs, r, and response, u(r), one is provided with some sort of evaluation J(u,r), and -- if backpropagation is available -- one is also provided with the derivatives of J with respect to each component of u.
There are two conventional approaches to this problem widely used in adaptive critic systems. One approach -- when the choices are discrete -- is simply to consider all possible choices, or to use a method like Barto's Arp which is also extremely limited in handling large numbers of choices. Neither of these is adequate for handling very complex decisions with continuous aspects. Another approach is to use backpropagation, which introduces the possibility of getting caught in a local minimum. This possibility is typically not a big problem for lower-level action choices, but for large-scale decisions it can be extremely serious, because of the "lumpy" nature of large-scale choices. (An example might be the decision of where to place a stone on a Go board; each of the 381 legal grid points is a kind of "local optimum," superior to placing a stone on the illegal nearby sites off of the grid points. More generally, there is a problem in long-term decision-making of separating the forest from the trees, when seeking the highest point.) A third common alternative is the use of genetic algorithms at each time t, which would appear radically different from what the circuitry of the brain seems to suggest, and also seems unnecessarily slow for a real-time system.
This section will propose an alternative approach to this problem. In general, we propose the development and use of a Stochastic Action Network which has the property that:
![]() , (52)
, (52)
where Z is a kind of normalization function (similar to the partition functions of physics) set to insure that the probabilities all add up to one, where k is a constant, and where T -- "temperature" -- is a global parameter which can be changed over time. In effect, the SAN learns the "forest" instead of the "trees;" it provides options for actions or decisions. For a complete action system, one can simply use the SAN to continually suggest new alternatives (versus the previously chosen alternatives, whatever they may be), and one can update the actual action or decision vector whenever the new option looks better. In a way, these networks may be thought of as a kind of "imagination network." Note that the inputs to the SAN may include information about the previous decision, etc. Also, in the "Error Critic" design [8,chapter 13], one meet even generate the recurrent values, R, as an action vector in the SAN sense; such an architecture might occasionally produce wavering images of reality in certain situations (as is seen in real mammals).
There are several possible approaches to adapt SAN networks. In such networks, we begin by assuming we can generate vectors e made up of random variables from the usual normal distribution N(0,1). The SAN may then be written as:
![]() (53)
(53)
where A is the neural network.
One possible approach is to first strain a “DTQ” network which inputs
u and r and then tries to predict "F_e", the gradient of J(A(r,e,W),r) with respect to e. Let us write:
![]() (54)
(54)
We may try to adapt the weights W so as to minimize:
![]() (55)
(55)
The purpose of this is to make F_e equal e, as it would for the desired normal distribution. In effect, this is arbitrarily choosing a particular value for kT, but by scaling up e in proportion to T one can achieve any desired thermal distribution, especially if T is varied during training, with the adjustments scaled accordingly. Notice that it would be very critical to adapt the DTQ net as quickly or more quickly than we adapt the A network. A more rigorous approach would be to avoid the DTQ network, and directly minimize (F_e-e)2, which requires the use of second-order backpropagation, discussed in several sources, such as [8,chapter 10].
One should be warned that these designs have only received a very limited amount of convergence analysis so far, only in the linearized case. Thus it is possible that a variant using an SEDP-based design to provide the SAN component may be worth exploring.
The global "temperature" T is theoretically arbitrary. However, numerous authors, such as Levine and Leven[11], have discussed how variations in "novelty seeking" (which T represents) can serve the motivations of organisms. Although the rules for adjusting T cannot be specified in a rigid way apriori, they -- like the measures of success used in weighting g+ training , discussed in section 3.3 -- provide an important aspect of the "cognitive style" or "personality" of the intelligent system.
In the mammalian brain, it is very interesting that the lower layers of the neocortex -- the most recent part of the brain -- provide both the state estimation (with Error Critic, we have argued[1]) and a kind of stochastic SAN-like output to the basal ganglia, where discrete choices are enforced. Clearly that arrangement fits in with the spirit of this design.
5 Adding the Third
Brain
Strictly speaking, the architecture described above corresponds to the "upper brain" and "middle brain" as described in [1]. For reasons discussed in [1], this system cannot operate at the maximal sampling rate which the underlying hardware seems capable of. In order to perform true maximal-rate real-time control, one can simply add a "third brain" -- a straightforward adaptive critic system as described in [8,chapter 13] and in [1], parallel to the olive-cerebellum system of the brain. As described in [1] (which is incorporated here by reference), one can link this lower-level system to the upper-level system by a simple master-slave arrangement, in which changes in the lowest-level J from the upper system are used to generate the main component of the "U" function maximized over time by the lower system. Also, for the sake of parsimony, it is easiest to define the action outputs of this lower brain relative to the lowest-level action "decisions" of the upper brain; in other words, we can calculate the total actual u as the sum of the lower-level u plus the most recent u output from the upper level. This would correspond to the arrangement in the mammalian brain, in which outputs from motor cortex are added to outputs from the olive-cerebellum system, so as to generate smooth, coordinated movement.
References
[1] P.Werbos, “Learning in the brain: an engineering interpretation”, in Learning as Self-Organization, K.Pribram, Ed., Erlbaum, 1996.
[2] P. Werbos, “Neurocontrollers”, in Encyclopedia of Electronics and Electrical Engineering, J.Webster, Ed., Wiley, forthcoming. (Draft version incorporated into patent.)
[3] R. Howard Dynamic Programming and Markhov Processes, MIT Press, 1960.
[4] P.Werbos, “The cytoskeleton: Why it may be crucial to human learning and to neurocontrol”, Nanobiology, Vol. 1, No.1, 1992.
[5] D.P.Bertsekas and J.N.Tsitsiklis, Neurodynamic Programming, Athena Scientific,
[6] R.Sutton, “TD Models: Modeling the World at a Mixture ofTime Scales.” CMPSCI Technical Report 95-114. U.Mass. Amherst, December 1995, later published in Proc. 12th Int. Conf. Machine Learning, 531-539, Morgan Kaufmann, 1995.
[7] J.Albus, Outline of Intelligence, IEEE Trans. Systems, Man and Cybernetics, Vol.21, No.2, 1991.
[8] D.White and D. Sofge, eds, Handbook of Intelligent Control, Van Nostrand, 1992.
[9]
[10] H.Ritter, T.Martinetz, and K.Schulten, Neural Computation and Self- Organizing Maps, Addison-Wesley, 1992.
[11] D.S.Levine and S.J.Leven, Motivation, Emotion, and Goal Direction in Neural Networks, Erlbaum, 1992.
[12] P.Werbos &
X.Z.Pang, “Generalized maze navigation: SRN critics solve what feedforward or Hebbian nets
cannot”, Proc. Conf. Systems, Man and Cybernetics (SMC) (
[13] X.Z.Pang & P.Werbos, “Neural network design for J function approximation in dynamic programming”, Math. Modelling and Scientific Computing (a Principia Scientia journal), special issue on neural nets, winter 1996-1997
[14] P.Werbos, “Supervised learning: can it escape its local minimum”, WCNN93 Proceedings, Erlbaum, 1993. Reprinted in Theoretical Advances in Neural Computation and Learning, V. Roychowdhury et al, Eds., Kluwer, 1994
[15] D.Levine and
[16] P.Werbos, “Optimal neurocontrol: Practical benefits, new results and biological evidence”, Proc.World Cong. on Neural Networks(WCNN95), Erlbaum, 1995
[17] P.Werbos, “Optimization methods for brain-like intelligent control”, Proc. IEEE Conf. CDC, IEEE, 1995.
[18] P.Werbos, The Roots of Backpropagation: From Ordered Derivatives to Neural Networks and Political Forecasting, Wiley, 1994.
[19] P.Werbos, “Values, goals and utility in an engineering-based theory of mammalian intelligence” in Brain and Values, K.Pribram ed., Erlbaum, 1997.
[20] K.Pribram, Brain and Perception: Holonomy and Structure in Figural Processing, Erlbaum 1991.